Software Release - fwsnort-1.6.3
22 December, 2012
 The 1.6.3 release of fwsnort is
available for download. This release
adds a new test suite in the test/ directory that sends fwsnort through its paces
for both iptables and ip6tables firewalls, speeds up iptables/ip6tables capabilities
testing, and fixes a few bugs. In addition, one of the more significant changes is to
ensure that Snort rules with HOME_NET=any -> EXTERNAL_NET=any are placed into the
OUTPUT chain instead of the INPUT chain. This bug was reported by Dwight Davis. I would
also like to thank Franck Joncourt for his support on the Debian side. Other changes
were contributed by the open source community, and these are acknowledged in the complete
fwsnort-1.6.3 ChangeLog below:
The 1.6.3 release of fwsnort is
available for download. This release
adds a new test suite in the test/ directory that sends fwsnort through its paces
for both iptables and ip6tables firewalls, speeds up iptables/ip6tables capabilities
testing, and fixes a few bugs. In addition, one of the more significant changes is to
ensure that Snort rules with HOME_NET=any -> EXTERNAL_NET=any are placed into the
OUTPUT chain instead of the INPUT chain. This bug was reported by Dwight Davis. I would
also like to thank Franck Joncourt for his support on the Debian side. Other changes
were contributed by the open source community, and these are acknowledged in the complete
fwsnort-1.6.3 ChangeLog below:
- Bug fix to ensure that !, <, >, and = chars in content strings are
converted to the appropriate hex equivalents. All content strings with
characters outside of [A-Za-z0-9] are now converted to hex-string format
in their entirety. This should also fix an issue that results in the
following error when running /var/lib/fwsnort/fwsnort.sh:
Using intrapositioned negation (`--option ! this`) is deprecated in favor of extrapositioned (`! --option this`). Bad argument `bm' Error occurred at line: 64 Try `iptables-restore -h' or 'iptables-restore --help' for more information. Done. - Bug fix to set default max string length in --no-ipt-test mode where iptables capabilities are not tested.
- (Andrew Merenbach) Bug fix to properly honor --exclude-regex filtering option.
- Added fwsnort test suite to the test/ directory. This mimics the test suites from the psad and fwknop projects, and it designed to examine many of the run time results of fwsnort.
- Added the ability to easily revert the fwsnort policy back to the original iptables policy with "/var/lib/fwsnort/fwsnort.sh -r". Note that this reverts back to the policy as it was when fwsnort itself was executed.
- Implemented a single unified function for iptables match parameter length testing, and optimized to drastically reduce run time for iptables capabilities checks (going from over 20 seconds to less than one second in some cases).
- (Dwight Davis) Contributed patches for several bugs including not handling --exclude-regex properly, not ignoring the deleted.rules file, not handling --strict mode operations correctly, and more. These issues and the corresponding patch were originally reported here: http://bugs.debian.org/cgi-bin/bugreport.cgi?bug=693000
- Bug fix for Snort rules with HOME_NET(any) -> EXTERNAL_NET(any) to ensure they go into the OUTPUT chain instead of the INPUT chain. This bug was reported by Dwight Davis.
- Updated to bundle the latest Emerging Threats rule set.


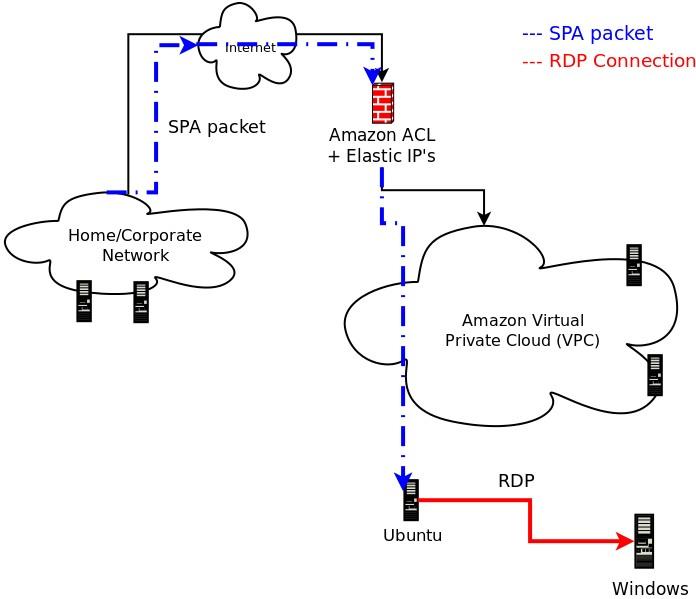
 Given this graph, it is apparent that Rijndael comes pretty close to producing data that looks
quite random across every byte position and there are no significant outliers. Now, let us run
the spa-entropy.pl script in --gpg mode in order to instruct the fwknop client to generate
SPA packets that are encrypted with GnuPG:
Given this graph, it is apparent that Rijndael comes pretty close to producing data that looks
quite random across every byte position and there are no significant outliers. Now, let us run
the spa-entropy.pl script in --gpg mode in order to instruct the fwknop client to generate
SPA packets that are encrypted with GnuPG:
 Wow, it is immediately apparent that there is something quite different about the measured entropy
for GnuPG SPA packets. There are three areas of interest: 1) the first four bytes, 2) two
bytes or so around byte 275, and 3) four bytes around byte 525. Why does the entropy fall
off so drastically at these locations? The first region is most likely an artifact of the
usage of the same GnuPG key across all SPA packets along with the fact that the fwknop client
only strips off the first two bytes if they match the string "hQ" in the base64 encoded SPA
data. This string corresponds to the same values that the /etc/magic database
provides to the file command - it is the same across all GnuPG encrypted data regardless
of which keys are used. But, the next four bytes aren't as predictable, and must vary from
key to key so the fwknop client can't use a simple strategy of removing these bytes before an
SPA packet is placed on the wire. (The whole reason for removing the bytes in the first place
is to make it slightly more difficult to write a simplistic Snort signature for SPA packet
detection.) The next two regions can be explained by the fact that the OpenPGP protocol
(see:
Wow, it is immediately apparent that there is something quite different about the measured entropy
for GnuPG SPA packets. There are three areas of interest: 1) the first four bytes, 2) two
bytes or so around byte 275, and 3) four bytes around byte 525. Why does the entropy fall
off so drastically at these locations? The first region is most likely an artifact of the
usage of the same GnuPG key across all SPA packets along with the fact that the fwknop client
only strips off the first two bytes if they match the string "hQ" in the base64 encoded SPA
data. This string corresponds to the same values that the /etc/magic database
provides to the file command - it is the same across all GnuPG encrypted data regardless
of which keys are used. But, the next four bytes aren't as predictable, and must vary from
key to key so the fwknop client can't use a simple strategy of removing these bytes before an
SPA packet is placed on the wire. (The whole reason for removing the bytes in the first place
is to make it slightly more difficult to write a simplistic Snort signature for SPA packet
detection.) The next two regions can be explained by the fact that the OpenPGP protocol
(see: 
 .
.




